SERDES (SERializer/DESerializer) là khối mạch chuyển đổi giữa dữ liệu song song (parallel) bên trong chip và dữ liệu nối tiếp (serial) truyền trên đường dây tốc độ cao. Đây là nền tảng của hầu hết các giao tiếp tốc độ cao mà bạn làm việc hàng ngày: PCIe, SATA, Ethernet (25G NIC), USB, SAS…
Tại sao cần SERDES?
Bên trong chip, dữ liệu di chuyển theo bus song song (8, 16, 32 bit) với tốc độ xung nhịp tương đối thấp. Nhưng nếu truyền song song ra ngoài qua nhiều dây, sẽ gặp vấn đề:
Skew giữa các đường dây (mỗi bit đến đích lệch thời điểm nhau).
Số chân (pin) và dây quá nhiều, tốn diện tích board và chân BGA.
Nhiễu xuyên âm (crosstalk) giữa các đường.
Giải pháp: gom dữ liệu song song lại, truyền nối tiếp trên một cặp dây vi sai (differential pair) ở tần số rất cao. Đó chính là một “lane” trong PCIe hay một cặp TX/RX trong SATA.
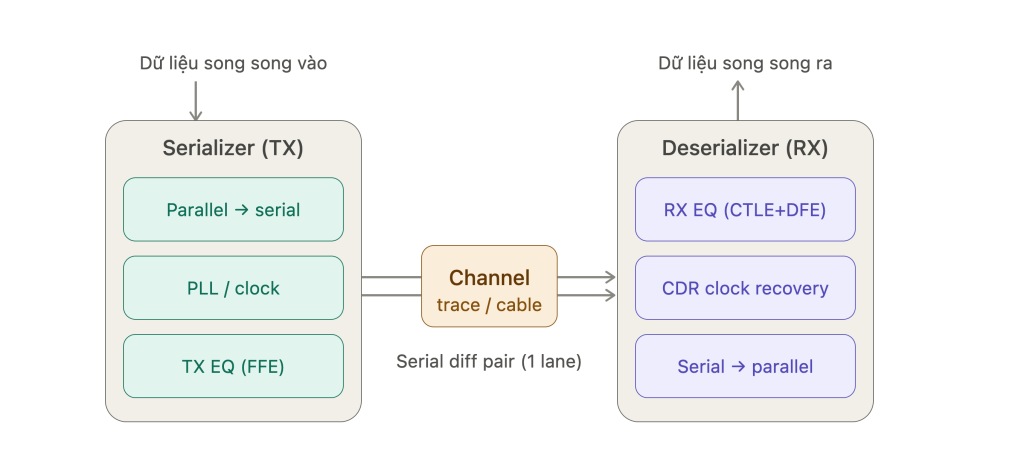
SERDES không phải một khối đơn lẻ mà là một cặp khối ở hai đầu link: phía phát (TX) serialize dữ liệu, phía thu (RX) deserialize lại. Sơ đồ đường dữ liệu:
(Sơ đồ luồng dữ liệu của một link SERDES)
Phía phát — Serializer (TX)
Dữ liệu song song từ logic bên trong chip (8/16/32 bit) đi vào và được “gom” thành luồng nối tiếp.
PLL/clock: tạo xung nhịp tốc độ cao (bit clock). Ví dụ PCIe Gen3 chạy 8 GT/s nghĩa là PLL phải tạo nhịp ở mức GHz.
TX equalizer (FFE / pre-emphasis, de-emphasis): đường truyền (PCB trace, connector) làm suy hao tín hiệu tần số cao nhiều hơn tần số thấp. TX “bù trước” bằng cách nhấn mạnh các transition để khi tới đích tín hiệu cân bằng lại. Đây là tham số bạn hay thấy trong PCIe gọi là TX preset.
Kênh truyền (Channel)
Cặp dây vi sai truyền nối tiếp — chính là một lane. Đây là phần “xấu”: suy hao theo tần số (insertion loss), phản xạ (return loss), nhiễu xuyên âm (crosstalk), jitter. Chất lượng channel quyết định link có train được lên tốc độ cao hay không — ví dụ lỗi khi lane chỉ train được 4x1 thay vì 4x2.
Phía thu — Deserializer (RX)
RX equalizer (CTLE + DFE): CTLE (Continuous-Time Linear Equalizer) khôi phục các tần số cao bị suy hao; DFE (Decision Feedback Equalizer) khử phần đuôi tín hiệu (ISI – inter-symbol interference) từ các bit trước đó.
CDR (Clock and Data Recovery): điểm mấu chốt của SERDES. Tín hiệu nối tiếp truyền đi không kèm clock riêng (embedded clock), nên RX phải tự khôi phục xung nhịp từ chính các transition của dữ liệu. Đây là lý do cần mã hóa dòng (line coding) như 8b/10b (PCIe Gen1/2, SATA) hoặc 128b/130b (PCIe Gen3+) — để đảm bảo đủ transition cho CDR bám.
Serial → parallel: tách luồng nối tiếp trở lại bus song song cho logic phía sau.
Một số khái niệm SERDES bạn sẽ gặp khi debug:
Eye diagram: cách trực quan đánh giá chất lượng SERDES — “mắt” càng mở (cao và rộng) thì biên độ và biên thời gian (timing margin) càng tốt.
Link training: lúc PCIe/Ethernet thương lượng tốc độ và tinh chỉnh TX preset / RX EQ. Lỗi training thường do channel kém, contact hở (như case bus 86 bạn từng phân tích), hoặc EQ chưa tối ưu.
PRBS / loopback test: ở môi trường manufacturing, đo BER bằng pattern giả ngẫu nhiên (PRBS) qua loopback là cách kiểm tra chất lượng SERDES của một lane.
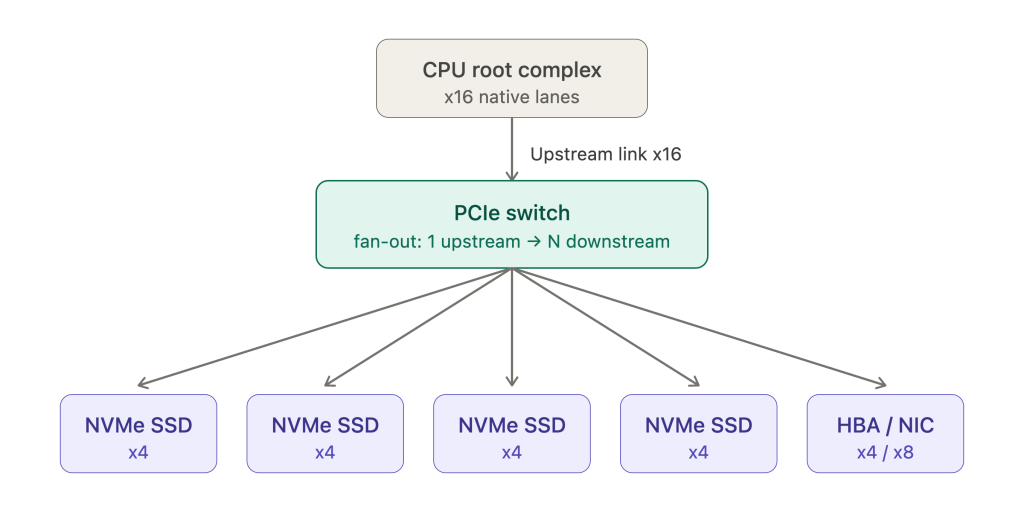
PCIe fan-out switch là một con chip switch PCIe dùng để lấy một link PCIe upstream (thường từ CPU root complex) rồi “trải” (fan-out) ra thành nhiều downstream port để kết nối đồng thời tới nhiều thiết bị endpoint.
Bản chất nằm ở chỗ PCIe là kiến trúc point-to-point – mỗi link chỉ nối trực tiếp hai thiết bị, và root complex của CPU chỉ có số lane giới hạn (vd Gen4/Gen5 x16). Khi cần kết nối nhiều thiết bị hơn số lane native cho phép, ta đặt một con switch vào giữa: nó có 1 upstream port và N downstream port, định tuyến TLP (Transaction Layer Packets) giữa upstream và các downstream dựa trên address/ID routing.
Hình 1. Một upstream link x16 được fan-out thành nhiều downstream x4 tới các endpoint.
Ví dụ điển hình ngay trong domain của bạn: một storage server có cả chục ổ U.2 NVMe nhưng CPU không đủ lane để cấp x4 native cho từng ổ. Backplane NVMe nhiều khe vì vậy luôn có một (hoặc nhiều) con switch lấy x16 upstream rồi fan-out thành nhiều downstream x4. HBA/retimer/NIC cũng thường treo dưới switch theo kiểu này.
Một số điểm kỹ thuật đáng lưu ý khi debug:
Oversubscription – tổng bandwidth downstream thường lớn hơn upstream (vd 24 ổ × x4 = 96 lane downstream nhưng chỉ x16 upstream). Bình thường không sao, nhưng khi nhiều ổ I/O nặng đồng thời thì bottleneck nằm ở upstream link, không phải ở ổ.
Link training từng port độc lập – mỗi downstream port của switch train riêng. Đây chính là chỗ hay sinh ra các lỗi kiểu bạn vẫn gặp: port train xuống 4×1 thay vì 4×2/4×4, hoặc degrade speed (Gen4 → Gen1) do contact pin, signal integrity, hoặc seating của card/ổ. Khi đọc log, cần phân biệt rõ lỗi nằm ở link upstream switch ↔ CPU hay ở downstream switch ↔ endpoint – vì hướng xử lý (RMA chassis vs RMA drive/card) khác hẳn nhau.
Lspci topology – khi debug, switch hiện ra dưới dạng bridge: một upstream bridge + nhiều downstream bridge, endpoint nằm sau các downstream bridge đó. Đọc cây lspci -tv sẽ thấy rõ ổ nào treo dưới switch nào, hữu ích để khoanh vùng xem một loạt ổ cùng fail có phải do chung một con switch không.
NTB (Non-Transparent Bridging) – một số switch hỗ trợ multi-host / dual-controller, cho phép hai host cùng “nhìn” vào một miền PCIe qua bridge không trong suốt. Liên quan tới các bài dual-controller storage.
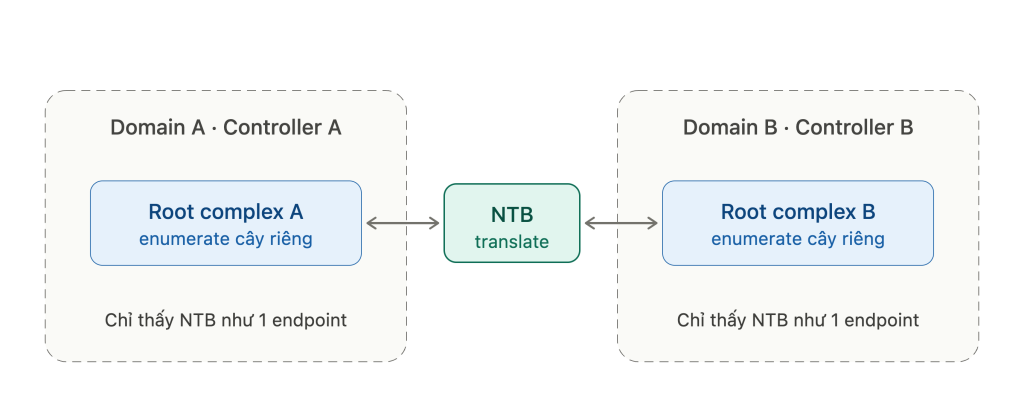
NTB là tính năng thú vị nhất của PCIe switch, và đúng là phần cốt lõi đằng sau kiến trúc dual-controller mà các unit bạn đang test sử dụng. Để hiểu NTB, trước hết cần đối chiếu với bridge thường:
Một transparent bridge (TB) – chính là downstream port bình thường của switch – thì “trong suốt”: root complex nhìn xuyên qua nó và enumerate được mọi thiết bị phía sau. Cả cây PCIe chỉ có một root complex, một address domain, một chủ sở hữu duy nhất. Đây là lý do bạn không thể cắm hai CPU/host vào cùng một cây PCIe – cả hai sẽ cùng đòi làm root complex, cùng enumerate, cùng đòi sở hữu config space và address space → xung đột ngay.
Non-transparent bridge (NTB) giải quyết đúng vấn đề đó. Thay vì hiện ra như một bridge để nhìn xuyên qua, NTB trình diện với mỗi bên như một endpoint (một thiết bị có BAR). Quá trình enumerate của Host A dừng lại ngay tại NTB – nó chỉ thấy “một endpoint”, không cố enumerate cây phía bên kia. Host B cũng vậy. Nhờ đó hai domain PCIe độc lập (hai root complex) có thể nối với nhau mà không bên nào giẫm chân bên nào.
Hình 2. NTB nối hai domain PCIe độc lập; mỗi bên chỉ thấy NTB như một endpoint.
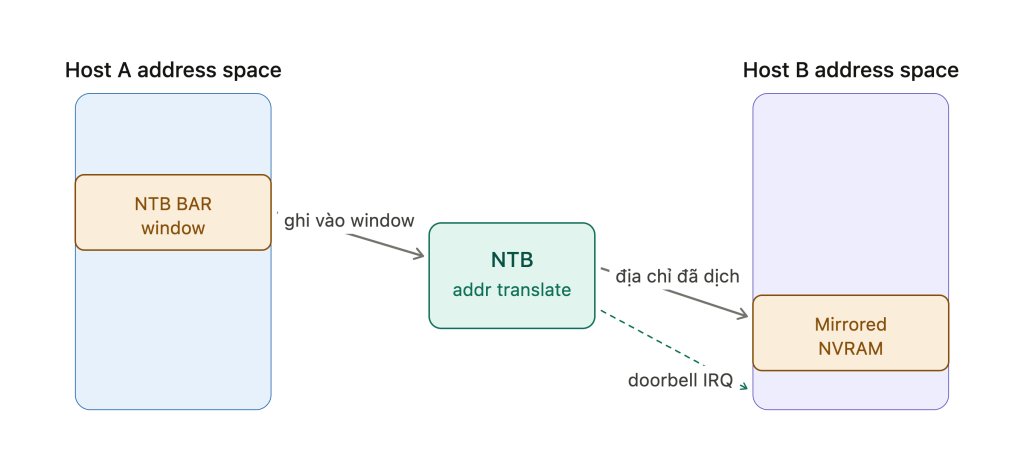
Vậy hai bên trao đổi dữ liệu với nhau bằng cách nào? NTB cung cấp một cơ chế address translation giữa hai domain. Mỗi bên có các BAR window map vào không gian địa chỉ của mình; khi một bên ghi vào window đó, NTB dịch địa chỉ sang địa chỉ tương ứng trong domain bên kia rồi forward transaction qua. Ngoài ra còn ba thành phần phụ trợ quan trọng:
Doorbell registers: một bên ghi vào doorbell để phát interrupt/tín hiệu sang bên kia (“dữ liệu đã ghi xong, xử lý đi”).
Scratchpad registers: thanh ghi dùng chung cả hai bên đọc/ghi được, dùng để handshake, trao đổi trạng thái.
Requester ID translation: vì hai domain đánh số Bus/Device/Function riêng, NTB phải dịch cả requester ID để completion route ngược về đúng chỗ.
Ví dụ cụ thể — write-cache mirroring trong dual-controller array (đúng kiến trúc Pure):
Một array có Controller A và Controller B, mỗi controller có CPU/root complex riêng, nối với nhau qua switch có NTB. Khi Controller A nhận một write từ host, trước khi ACK về cho host, nó bắt buộc phải mirror dữ liệu sang NVRAM của Controller B — để nếu A chết đột ngột thì B vẫn còn dữ liệu, không mất write (đảm bảo durability). Luồng diễn ra đúng như hình trên: A DMA dữ liệu qua NTB window → NTB dịch địa chỉ → dữ liệu hạ cánh vào NVRAM của B → A rung doorbell báo B. Độ trễ chỉ cỡ micro-giây vì đi thẳng qua PCIe, không phải đóng gói qua TCP/IP hay thậm chí RDMA. Khi failover, B đã có sẵn dữ liệu và tiếp quản các ổ.
Khi debug, đây cũng là lý do trên một số unit bạn thấy trong lspci có một “endpoint” lạ với vài BAR lớn nằm giữa hai miền — đó chính là NTB, không phải card hỏng.
Giờ phân tích điểm mạnh / điểm yếu:
Điểm mạnh
Độ trễ cực thấp & băng thông cao: giao tiếp PCIe native, không có overhead protocol stack. Lý tưởng cho mirroring cache, heartbeat, coordination giữa hai controller.
Cách ly lỗi (fault isolation) — đây chính là lý do tồn tại của NTB: hai domain độc lập, nên một bên crash/reset/re-enumerate hay reboot không kéo bên kia sập theo. Mỗi controller boot độc lập được. Với HA storage đây là yêu cầu sống còn.
Offload bằng phần cứng: DMA engine + doorbell + scratchpad cho phép trao đổi không tốn nhiều CPU.
Rẻ và đơn giản hơn so với gắn thêm cặp RDMA NIC chỉ để nối hai host ở cự ly gần trong cùng chassis.
Điểm yếu
Phức tạp về phần mềm: phải cấu hình BAR window, LUT (lookup table) cho address translation, quản lý mapping — driver không hề tầm thường.
Window/LUT có giới hạn: cửa sổ dịch địa chỉ có kích thước và số entry hữu hạn, nên không “phơi” tùy ý toàn bộ RAM bên kia được; map vùng nhớ lớn/động khá vướng.
Phụ thuộc vendor nặng: NTB của Broadcom/PLX, Microchip (Switchtec), Intel… khác nhau về thanh ghi và cấu hình. Linux có lớp ntb chung nhưng phần cứng bên dưới vẫn không portable.
Cự ly ngắn: PCIe là short-reach, chỉ trong chassis hoặc cáp ngoài ngắn — không dùng cho khoảng cách xa.
Xử lý lỗi & hot-plug xuyên bridge phức tạp: phải chặn không cho fatal error của một bên lan sang bên kia; error containment cần thiết kế cẩn thận.
Bề mặt tin cậy/bảo mật: NTB cho một host một “cửa sổ” ghi thẳng vào bộ nhớ host kia — hai bên buộc phải tin nhau hoàn toàn.
Khó mở rộng: về cơ bản là point-to-point giữa 2 domain; multi-host NTB có tồn tại nhưng độ phức tạp tăng nhanh.
Một lưu ý cho bức tranh hiện tại: với nhu cầu chia sẻ/gộp bộ nhớ giữa nhiều host, CXL đang dần thay thế NTB ở các thiết kế mới (cache-coherent, mô hình lập trình sạch hơn). Nhưng cho bài toán mirroring low-latency giữa hai controller trong cùng array thì NTB vẫn rất phổ biến và đáng tin trên các nền tảng đang sản xuất.
Pull request là một yêu cầu đề xuất thay đổi code. Trong quy trình phát triển phần mềm, nhà phát triển gửi pull request để đề xuất và thảo luận về sự thay đổi trước khi hợp nhất chúng vào mã nguồn chính, tạo cầu nối mượt mà giữa các đội và đảm bảo chất lượng mã nguồn.
Pull request là gì? (Nguồn: TopOnSeek)
1. Pull Request là gì?
Trong việc quản lý mã nguồn và lập trình trong các dự án sử dụng hệ thống quản lý phiên bản Git, Pull Request (hay yêu cầu kéo) là một yêu cầu được gửi bởi một lập trình viên để thông báo cho người quản lý dự án hoặc các đồng nghiệp rằng họ đã hoàn thành một tập hợp các thay đổi trong mã nguồn và muốn hợp nhất (merge) những thay đổi đó vào nhánh chính của dự án.
Để đóng góp vào một dự án, người dùng thường tạo một nhánh riêng từ nhánh chính (gọi là nhánh master), thực hiện thay đổi cần thiết, sau đó gửi những thay đổi này lên remote repository và tạo pull request. Pull request chứa thông tin về thay đổi đã thực hiện, các commit mới, nhận xét, v.v. Các Admin (hay là các chủ dự án) hoặc các thành viên khác có thể xem xét trước khi quyết định chấp nhận hay từ chối.
Khi được chấp nhận, thay đổi trong pull request được hợp nhất vào nhánh chính của dự án. Quá trình này có thể tự động hóa qua công cụ tích hợp với hệ thống quản lý mã nguồn.
Pull request là phương pháp an toàn và linh hoạt để đóng góp vào dự án, đảm bảo thay đổi mới không ảnh hưởng tiêu cực đến mã nguồn hiện tại.
2. Tại sao Pull Request quan trọng đến vậy?
Pull request rất quan trọng trong quá trình phát triển phần mềm, đặc biệt khi làm việc với nhóm trong các dự án mã nguồn mở. Vậy thì những lợi ích của pull request là gì?
Tăng cường tính minh bạch và thúc đẩy sự tham gia của cộng đồng
Pull request giữ vai trò quan trọng trong việc tăng cường tính minh bạch và thúc đẩy sự tham gia của cộng đồng trong dự án mã nguồn mở.
Khi một pull request được tạo, nó mở ra cơ hội cho cả cộng đồng xem xét, thảo luận và đóng góp ý kiến, làm cho quá trình phát triển mã nguồn trở nên rõ ràng và dễ dàng theo dõi. Sự tham gia này không chỉ giúp cải thiện chất lượng mã nguồn mà còn xây dựng tinh thần hợp tác trong cộng đồng, tạo nên một môi trường làm việc chuyên nghiệp, hỗ trợ và học hỏi lẫn nhau.
Kiểm tra chất lượng mã nguồn
Pull Request đóng một vai trò quan trọng trong việc đảm bảo chất lượng mã nguồn trong các dự án phần mềm. Chức năng này tạo điều kiện cho các thành viên khác trong nhóm có cơ hội kiểm tra và xem xét mã nguồn mới trước khi nó được hợp nhất vào nhánh chính.
Quá trình này không chỉ giúp phát hiện và sửa chữa các lỗi hoặc vấn đề về mã nguồn một cách sớm nhất, mà còn ngăn chặn việc áp dụng các thay đổi không mong muốn, từ đó đảm bảo rằng mã nguồn luôn duy trì ở trạng thái chất lượng cao.
Khi tất cả các thay đổi trên mã nguồn đều được xem xét và kiểm tra kỹ lưỡng thông qua pull request trước khi hợp nhất, điều này giúp tránh được các lỗi và xung đột tiềm ẩn, đóng góp vào sự ổn định và tin cậy của mã nguồn trong quá trình phát triển.
Chất lượng và lịch sử mã nguồn
Pull Request giúp người tham gia dự án đóng góp thay đổi vào mã nguồn một cách dễ dàng, tạo điều kiện cho quá trình kiểm tra và chấp nhận các thay đổi trở nên đơn giản hơn. Mỗi Pull Request đi kèm với bình luận, đánh giá và quá trình thảo luận, tạo ra một lịch sử chi tiết về việc thay đổi mã nguồn. Điều này không chỉ giúp các thành viên trong nhóm dễ dàng theo dõi và hiểu rõ hơn về quá trình phát triển, mà còn giúp họ nắm bắt được lý do đằng sau các quyết định đã được đưa ra.
3. Quá trình các bước tạo Pull Request
Sau khi tìm hiểu những lợi ích của pull request là gì, thì giờ là lúc thực hành tạo lệnh pull request.
Bước 1: Fork dự án gốc
Truy cập vào dự án gốc trên GitHub.
Nhấn vào nút “Fork” ở góc trên bên phải để sao chép dự án vào tài khoản của bạn.
Bước 2: Clone dự án về máy
Truy cập vào repository đã fork trong tài khoản của bạn.
Sao chép URL của repository.
Mở Terminal và sử dụng lệnh git clone để clone dự án về máy.
Bước 3: Tạo nhánh mới
Mở Terminal trong thư mục dự án đã clone.
Sử dụng lệnh git checkout -b [tên_nhánh] để tạo và chuyển đổi sang một nhánh mới.
Bước 4: Thực hiện thay đổi
Mở dự án trong trình chỉnh sửa mã nguồn.
Thực hiện các thay đổi cần thiết và lưu lại.
Bước 5: Commit và Push
Mở Terminal và sử dụng lệnh git add . để thêm các thay đổi vào danh sách commit.
Sử dụng lệnh git commit -m “Mô tả commit” để commit các thay đổi đã thêm.
Sử dụng lệnh git push origin [tên_nhánh] để đẩy thay đổi lên repository của bạn trên GitHub.
Bước 6: Tạo Pull Request
Truy cập vào repository của bạn trên GitHub.
Nhấn vào nút “Compare & pull request” bên cạnh tên nhánh của bạn.
Điền thông tin cần thiết, mô tả về Pull Request và nhấn “Create Pull Request“.
Bước 7: Kiểm tra và xử lý yêu cầu chỉnh sửa
Nhóm quản lý dự án sẽ xem xét và thảo luận về Pull Request của bạn.
Nếu cần chỉnh sửa, bạn chỉ cần thêm commit vào nhánh đã tạo và Pull Request sẽ tự động cập nhật.
Bước 8: Pull Request được chấp nhận và merge
Sau khi Pull Request đạt yêu cầu, nhóm quản lý sẽ chấp nhận và merge vào nhánh chính.
Code của bạn đã được hợp nhất vào dự án gốc.
4. Kết luận
Tóm lại, quy trình tạo Pull Request trên nền tảng GitHub đóng một vai trò trung tâm trong quản lý và phát triển phần mềm theo đội ngũ. Việc này không chỉ giúp đảm bảo rằng mọi thay đổi đều được kiểm tra kỹ lưỡng trước khi hợp nhất vào nhánh chính của dự án, mà còn tạo ra một kênh giao tiếp mạnh mẽ giữa các thành viên trong dự án. Pull Request không chỉ là một công cụ kỹ thuật, mà còn là một phương pháp hợp tác, giúp xây dựng và duy trì một môi trường làm việc tích cực, đồng thuận và hiệu quả.
Cách tạo pull request?
Cách tạo pull request bao gồm 8 bước: Bước 1: Fork dự án gốc Bước 2: Clone dự án về máy Bước 3: Tạo nhánh mới Bước 4: Thực hiện thay đổi Bước 5: Commit và Push Bước 6: Tạo Pull Request Bước 7: Kiểm tra và xử lý yêu cầu chỉnh sửa Bước 8: Pull Request được chấp nhận và merge
Pull request vs Merge request?
Hai khái niệm này đều có ý nghĩa giống nhau, đó là đề xuất được hợp vào nhánh chính của một dự án. Khi pull request được chấp nhận, nhánh phụ sẽ được “merge” vào nhánh chính. Thế nên, pull request và merge request là hoàn toàn giống nhau.
Card adapter bus cho máy chủ (Card HBA) là một bảng mạch và / hoặc Card IC cung cấp quá trình xử lý đầu vào / đầu ra (I / O) và kết nối vật lý giữa máy chủ và thiết bị lưu trữ. Vì Card HBA làm giảm gánh nặng cho bộ xử lý chủ trong các tác vụ lưu trữ và truy xuất dữ liệu, nên nó có thể cải thiện hiệu suất máy chủ. Card HBA và một hệ thống con đĩa được kết nối với nó đôi khi được gọi là kênh đĩa.
Định nghĩa chung về Card HBA – Card I/O kết nối bus I/O máy chủ và hệ thống bộ nhớ máy tính. Theo định nghĩa này, giống như card màn hình được kết nối với máy tính và bộ nhớ, NIC được kết nối với bus mạng và bộ nhớ, card SCSI-FC được kết nối với bus và bộ nhớ SCSI hoặc FC, chúng nên được coi là Card HBA. Card HBA bao gồm FC-Card HBA và iSCSI Card HBA và các Card HBA khác trong tương lai, nhưng Card HBA thường được sử dụng trong SCSI. Card (adapter) và NIC được sử dụng cho FC, và NIC cũng được sử dụng cho mạng Ethernet và Token Ring.
Chúng ta biết rằng một máy tính hầu hết được kết nối bởi hai bus (tất nhiên, tình hình thực tế sẽ khác nhau, ở đây chỉ nói đến tình huống phổ biến, đơn giản), một bus gọi là bus hệ thống, gọi khác là bus I / O. Bus hệ thống trên CPU, bộ nhớ, bộ nhớ đệm, v.v., bus I / O là thiết bị ngoại vi và hiện nay phổ biến nhất là bus PCI. Hai bus được kết nối bằng một chip hoặc mạch bắc cầu. Ví dụ như thành phố, có hai con đường chính, một đường thuộc khu hành chính, một đường thuộc khu thương mại, ở giữa có bùng binh, hai con đường chính nối với nhau, hệ thống xe buýt giống như chính. đường trong quận, và xe buýt I / O giống như trục đường chính trong khu thương mại. Đơn vị băng thông bus hệ thống và bus I / O là Gbyte cần ghi nhớ,
Mặc dù tốc độ bus I/O thấp hơn nhiều so với băng thông bus hệ thống, dù kết quả là Gbyte để đo lường và chúng ta biết tốc độ của các thiết bị ngoại vi, thường chỉ là vài trăm nghìn tỷ, thậm chí hàng chục k thôi, làm thế nào để điều phối công việc? Thật dễ dàng, chúng ta sẽ tổ chức các thiết bị ngoại vi, kết nối với bus I / O! Card HBA đề cập đến Máy chủ lưu trữ và I / O BUS trực tiếp là một bộ chuyển đổi, nhưng cũng giống như một thợ sửa ống nước thường nói “vượt qua kép”. Vai trò của Card HBA là đạt được giao thức kênh nội bộ PCI hoặc Sbus và chuyển đổi giữa giao thức Fibre Channel.
Tầm quan trọng của Card HBA
Trong hệ thống lưu trữ SAN ban đầu, máy chủ và việc truyền dữ liệu chuyển mạch là thông qua sợi quang, bởi vì máy chủ là lệnh SCSI cho thiết bị lưu trữ, không thể lấy giao thức IP mạng LAN thông thường, do đó, nhu cầu sử dụng FC truyền tải, vì vậy SAN này được gọi là FC-SAN, và sau đó xuất hiện trong gói giao thức IP SAN , có thể lấy mạng LAN thông thường, vì vậy được gọi là IP-SAN, điển hình nhất hiện nay là ISCSI phổ biến.
Hai phương pháp này cần thực hiện thao tác giải nén gói dữ liệu nặng, do đó hệ thống SAN hiệu suất cao yêu cầu một card mạng chuyên dùng để giải nén máy chủ để giảm gánh nặng cho bộ xử lý. NIC này được gọi là Card HBA, tất nhiên ngoài công việc giải nén, còn có thể cung cấp giao diện sợi quang (nếu cạc iSCSI Card HBA cung cấp giao diện RJ45 chung) cho kết nối chuyển mạch tương ứng; Về mặt vật lý, bạn có thể cắm Card HBA vào khe cắm PCI hoặc PCI như một card mạng, vì vậy việc sử dụng thiết bị này giống như một card mạng, và nhiều người nhầm lẫn nó với một NIC thông thường hoặc một card cáp quang thông thường. Tất nhiên, một số card iSCSI Card HBA có thể được sử dụng như một card mạng bình thường, nhưng nếu xét về giá cả thì rất không kinh tế.
Nguyên tắc của Card HBA
Giao thức truyền thông dữ liệu phổ biến giữa máy chủ và thiết bị lưu trữ là IDE, SCSI và Fibre Channel. Để đạt được giao tiếp giữa máy chủ và thiết bị lưu trữ, cần có cùng một giao thức truyền thông ở cả hai đầu của giao tiếp. Cạc điều khiển thường có sẵn trên thiết bị lưu trữ và bộ điều khiển triển khai một hoặc nhiều giao thức truyền thông cho phép chuyển đổi giữa các giao thức lưu trữ như IDE, SCSI hoặc Fibre Channel sang các giao thức hoạt động của thiết bị lưu trữ vật lý.
Giao thức truyền thông của máy chủ được thực hiện bởi một mạch tích hợp của cạc mở rộng hoặc bo mạch chủ, chịu trách nhiệm chuyển đổi giao thức bus máy chủ và giao thức lưu trữ IDE và SCSI. Ví dụ: trong PC, các tính năng của giao thức IDE có trên bo mạch chủ và bộ điều khiển đĩa của IDE có giao thức IDE. Do đó, đĩa IDE có thể được kết nối với đầu nối IDE trên PC.
Nếu đĩa chỉ hỗ trợ giao thức SCSI, thì không thể kết nối trực tiếp đĩa với PC. Bạn cần lắp cạc SCSI trên khe cắm mở rộng của PC và đĩa SCSI có thể được kết nối với cạc. Card SCSI cho phép chuyển đổi bus PC sang SCSI. Loại cạc SCSI này nhận ra chức năng là chức năng card adapter Bus máy chủ. Nếu đĩa chỉ hỗ trợ các giao thức Fibre Channel, thì giao thức Fibre Channel là bắt buộc trên máy chủ vì đặc tính tốc độ cao của Fibre Channel không được hỗ trợ bởi Bo mạch chủ chung và yêu cầu một card adapter bus máy chủ chuyên dụng. Sau khi máy chủ được cắm vào card adapter bus máy chủ, nó có thể được kết nối với đĩa hỗ trợ kênh sợi quang.
Cạc adapter bus chủ bên trong có một CPU nhỏ, một số bộ nhớ làm bộ nhớ đệm dữ liệu và kết nối kênh cáp quang và các thiết bị kết nối bus. Bộ xử lý trung tâm nhỏ này chịu trách nhiệm chuyển đổi các giao thức PCI và Fibre Channel. Nó còn có một số chức năng khác để khởi tạo cổng máy chủ kết nối với mạng Fibre Channel, hỗ trợ các giao thức lớp trên như mã hóa và giải mã TCP / IP, SCSI, 8B / 10B.
Mối quan hệ giữa cạc giao diện mạng cáp quang Cạc (NIC) và Card HBA
Do giao thức truyền dẫn khác nhau, card mạng có thể được chia thành ba loại, một là card Ethernet, loại còn lại là card mạng Fibre Channel và ba là card mạng iSCSI.
Card mạng Ethernet – Tên của Card Ethernet, giao thức truyền tải là giao thức IP, thường được kết nối với bộ chuyển mạch Ethernet thông qua cáp quang hoặc cáp xoắn đôi. Các loại giao diện được chia thành cổng quang và cổng điện. Cổng quang thường được truyền qua cáp quang , module giao diện thường là SFP (tốc độ truyền GB) và GBIC (1GB / s), giao diện tương ứng là SC, ST và LC. Loại giao diện thường được sử dụng hiện nay là RJ45, nó được sử dụng để kết nối với xoắn đôi, cũng có giao diện với cáp đồng trục, nhưng hiện nay nó được sử dụng ít hơn.
FC Card mạng – hay còn gọi chung là card mạng cáp quang, tên khoa học là Fiber Channel Card HBA. Giao thức truyền tải là một giao thức Kênh Sợi và thường được kết nối với một bộ chuyển Kênh Sợi thông qua cáp quang . Loại giao diện được chia thành cổng quang và cổng điện. Giao diện quang thường thông qua cáp quang để truyền dữ liệu, mô-đun giao diện thường là SFP (tốc độ truyền 2Gb / s) và GBIC (1Gb / s), giao diện tương ứng cho SC và LC. Loại giao diện của giao diện điện nói chung là chân DB9 hoặc HSSDC.
ISCSI Card mạng – Tên của iSCSI Card HBA, giao thức Transport iSCSI và kiểu giao diện giống như card Ethernet.
Chúng tôi nói “card mạng cáp quang” thường đề cập đến cạc FC Card HBA, cắm vào máy chủ, bộ nhớ ngoài với bộ chuyển mạch quang; và cạc Ethernet quang thường được gọi là “Card Ethernet quang” cũng được đưa vào máy chủ, nhưng nó bên ngoài là bộ chuyển mạch Ethernet với cổng quang.
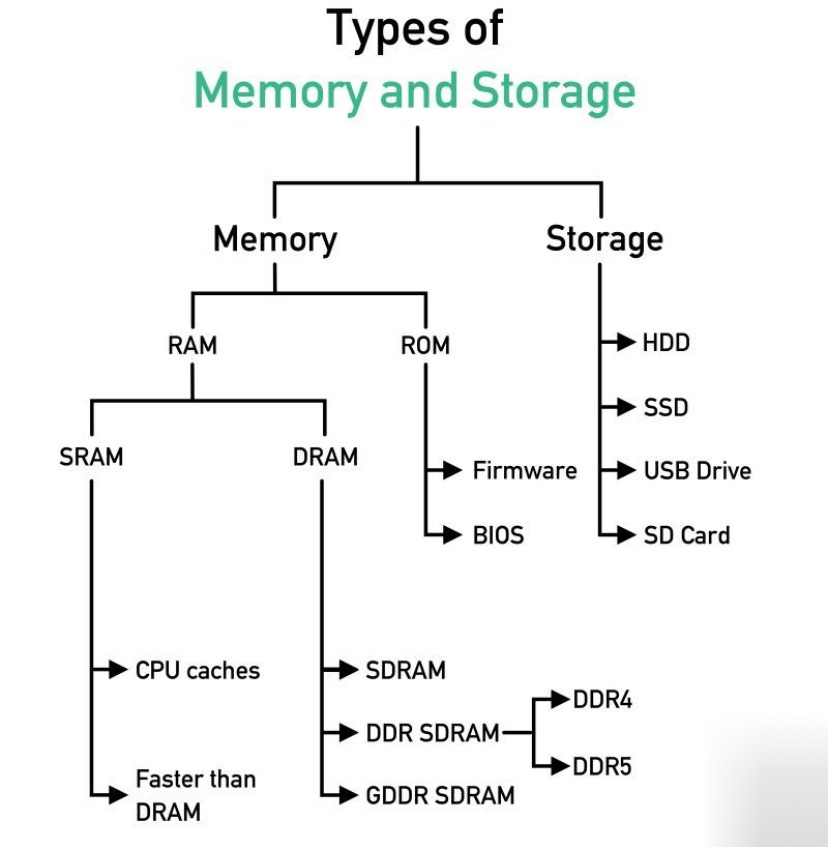
RAM (Bộ nhớ truy cập ngẫu nhiên): Bộ nhớ tạm thời, dễ mất dữ liệu khi tắt nguồn, dùng để lưu trữ dữ liệu trong lúc hệ thống đang hoạt động. Ví dụ: DDR4, DDR5.
ROM (Bộ nhớ chỉ đọc): Bộ nhớ không mất dữ liệu khi tắt nguồn, chứa firmware hoặc mã khởi động hệ thống.
DDR4 và DDR5
DDR4 (Double Data Rate 4): Thế hệ thứ tư của RAM, phổ biến trong các hệ thống hiện đại, có tốc độ cao, băng thông lớn và tiết kiệm điện năng.
DDR5 (Double Data Rate 5): Phiên bản nâng cấp của DDR4, cung cấp tốc độ truyền dữ liệu nhanh hơn, dung lượng lớn hơn và hiệu suất năng lượng tốt hơn.
Firmware và BIOS
Firmware: Phần mềm cố định được lập trình vào bộ nhớ chỉ đọc, kiểm soát hoạt động phần cứng ở cấp độ thấp.
BIOS (Hệ thống đầu vào/đầu ra cơ bản): Một dạng firmware đặc biệt, chịu trách nhiệm khởi tạo và kiểm tra phần cứng hệ thống khi khởi động trước khi bàn giao quyền kiểm soát cho hệ điều hành.
SRAM và DRAM
SRAM (Bộ nhớ tĩnh): RAM nhanh hơn và đắt hơn so với DRAM, không cần làm tươi (refresh) liên tục, thường được sử dụng làm bộ nhớ đệm (cache) trong CPU.
DRAM (Bộ nhớ động): RAM chậm hơn nhưng rẻ hơn SRAM, cần được làm tươi hàng nghìn lần mỗi giây, dùng làm bộ nhớ chính trong hầu hết các máy tính.
Thiết bị lưu trữ: HDD, SSD, USB Drive, Thẻ SD
HDD (Ổ cứng truyền thống): Thiết bị lưu trữ sử dụng đĩa từ quay, có dung lượng lớn với chi phí thấp nhưng tốc độ chậm hơn so với SSD.
SSD (Ổ cứng thể rắn): Sử dụng bộ nhớ flash, không có bộ phận chuyển động, tốc độ nhanh và bền hơn HDD nhưng chi phí cao hơn.
USB Drive (Ổ USB): Thiết bị lưu trữ di động, có thể ghi/xóa dữ liệu, tiện lợi để chuyển dữ liệu giữa các thiết bị.
SD Card (Thẻ nhớ SD): Dạng bộ nhớ flash di động, thường dùng trong máy ảnh, điện thoại thông minh và hệ thống nhúng.
SPI (tiếng Anh: Serial Peripheral Interface, tạm dịch: Giao diện Ngoại vi Nối tiếp) là một chuẩn truyền thông nối tiếp đồng bộ được sử dụng để truyền dữ liệu trong khoảng cách ngắn, thường được sử dụng trong các hệ thống nhúng. SPI được phát triển bởi Motorola vào giữa những năm 1980 và trở thành chuẩn de facto. Các ứng dụng tiêu biểu của SPI có thể kể đến như thẻ nhớ (Secure Digital cards) và giao tiếp màn hình LCD.
Các thiết bị hỗ trợ SPI giao tiếp ở chế độ chế độ song công toàn phần (full duplex), sử dụng mô hình master – slave với một master trên đường truyền. Thiết bị master khi đó sẽ khởi tạo frame cho việc gởi và nhận. Bus SPI hỗ trợ nhiều slave thông qua việc lựa chọn chân Chip Select (viết tắt: CS, hay còn gọi là Slave select, viết tắt là SS) kết nối từ master đến slave tương ứng với chân CS đó.
Đôi khi SPI cũng còn được gọi là bus nối tiếp bốn dây (four wire serial bus), để phân biệt với các loại bus nối tiếp đã có như three-wire, two-wire và one-wire.
Dù là một chuẩn truyền thông đồng bộ (khi yêu cầu xung clock để đồng bộ tín hiệu trên đường truyền) nhưng SPI khác với giao thức Synchronous Serial Interface (SSI), một giao thức truyền thông nối tiếp đồng bộ cũng sử dụng 4 dây. Giao thức SSI sử dụng dung sai tín hiệu và chỉ cung cấp một kênh truyền đơn hướng trong khi SPI hỗ trợ truyền thông giữa một master và nhiều slave.
Chân tín hiệu
Kết nối trên một SPI bus với một master và một slave
Bus SPI sử dụng 4 chân logic tín hiệu:
SCLK (Serial Clock): xung clock phát ra từ master
MOSI (Master Out Slave In): Dành cho việc truyền dữ liệu từ master đến slave. Chân MOSI ở master sẽ kết nối đến chân MOSI ở slave.
MISO (Master In Slave Out): Dành cho việc truyền dữ liệu từ slave đến master. Chân MISO ở master sẽ kết nối đến chân MISO ở slave.
CS/SS (Chip/Slave Select): Chân CS được master sử dụng để lựa chọn slave cần giao tiếp.
Ngoài ra, chân MOSI còn có các tên khác:
SIMO, MTSR: trên cả thiết bị master và slave
SDI, DI, DIN, SI: trên thiết bị slave
SDO, DO, DOUT, SO: trên thiết bị master
Chân MISO còn có các tên khác:
SOMI, MRST: trên cả thiết bị master và slave
SDO, DO, DOUT, SO: trên thiết bị slave
SDI, DI, DIN, SI: trên thiết bị master
Trong các thiết bị chỉ hoạt động ở chế độ slave, chân MOSI còn có tên SDI (Serial Data In) và MISO còn có tên SDO (Serial Data Out).
Chân Slave Select còn có các tên khác:
SS, SS, SSEL, nSS, /SS, SS# (slave select)
CS, CS (chip select)
CSN (chip select/enable)
CE (chip enable)
Hoạt động
Bus SPI hoạt động với một master với một hoặc nhiều slave.
Nếu một slave được master chọn để giao tiếp, chân SS khi đó sẽ được ghi mức LOW nếu slave này cho phép giao tiếp với master. Một số slave yêu cầu tín hiệu xung xuống ở chân SS để khởi tạo một kết nối master-slave, ví dụ như Maxim MAX1242 ADC, khi yêu cầu tín hiệu HIGH -> LOW. Với nhiều slave trên đường truyền SPI, mỗi slave này sẽ yêu cầu một chân SS tương ứng ở master cho quá trình giao tiếp.
Truyền dữ liệu
Truyền dữ liệu
Để bắt đầu quá trình truyền dữ liệu, master sẽ cấu hình xung clock để tương ứng với tần số hỗ trợ bởi slave, thường lên đến vài MHz. Master sau đó lựa chọn slave cần giao tiếp với chân SS tương ứng và ghi giá trị 0 lên chân này. Nếu có yêu cầu chờ trên đường truyền, ví dụ như quá trình chuyển đổi ADC đang diễn ra, master sẽ phải chờ trong khoảng thời gian đó trước khi khởi tạo xung clock.
Quá trình truyền dữ liệu song công diễn ra trên mỗi chu kỳ xung clock SPI. Master truyền một bit trên đường dây MOSI, và slave nhận bit này; cùng lúc đó, slave truyền một bit trên đường dây MISO và master nhận bit này. Quá trình này diễn ra kể cả khi master và slave chỉ cần thực thi truyền thông theo một chiều, ví dụ như master chỉ cần gởi data đến slave.
Quá trình truyền thường bao gồm 2 thanh ghi dịch với kích thước cố định, ví dụ như 8 bit, một thanh ghi dịch cho master và một thanh ghi dịch cho slave. Một cách trừu tượng, hai thanh ghi này được kết nối theo kiểu vòng. Khi đó, quá trình truyền sẽ bao gồm các bước:
Bước 1: Chân SS với slave tương ứng mà master muốn truyền/nhận sẽ được master ghi mức logic thấp
Bước 2: Bit MSB sẽ được truyền đi trước. Trong một xung clock, cả master và slave đều dịch ra 1 bit và đưa bit này đến bên slave hoặc master cần truyền tương ứng. Trong xung clock tiếp theo, ở mỗi bên nhận, bit được lấy mẫu trên đường truyền và được lưu như là bit LSB mới nhất trên thanh ghi dịch. Sau khi các bit trên thanh ghi dịch được đẩy ra hoặc đã nhận vào toàn bộ, cả master và slave đã hoàn tất việc trao đổi giá trị thanh ghi. Nếu nhiều data hơn cần được truyền đi, các thanh ghi dịch sẽ được load lại và quá trình trên được lặp lại.
Bước 3: Khi hoàn tất, master ngừng việc đảo xung clock và ngừng chọn chân SS với slave tương ứng. Khi đó chân SS sẽ được master ghi mức logic cao.
Việc truyền SPI thường là việc truyền 8 bit. Tuy nhiên cũng có các trường hợp mà nhiều hơn 8 bit được truyền đi, ví dụ như truyền 16 bit trong các bộ điều khiển màn hình cảm ứng hay các bộ giải mã tín hiệu âm thanh, như IC TSC2101 của Texas Instruments, hay truyến 12 bit với các bộ chuyển đổi DAC hoặc ADC.
Clock polarity và phase
Biểu đồ thời gian thể hiện CPOL và CPHA. Đường màu đỏ thể hiện xung SCK dẫn đầu, đường xanh thể hiện xung SCK còn lại.
Bên cạnh việc thiết lập tần số xung clock, SPI master còn phải cấu hình clock polarity (tạm dịch: cực của xung clock) và clock phase theo data. Tài liệu chính thức Motorola SPI Block Guide đặt tên 2 khái niệm này theo thứ tự là CPOL và CPHA (clock polarity và phase). 2 khái niệm này được dùng cho cả master và slave. Biểu đồ thời gian bên cạnh thể hiện CPOL và CPHA.
CPOL được xác định dựa trên xung SCK với:
CPOL = 0 khi xung dẫn đầu của 1 chu kỳ là xung cạnh lênh, xung còn lại là xung cạnh xuống.
CPOL = 1 khi xung dẫn đầu của 1 chu kỳ là xung cạnh xuống, xung còn lại là xung cạnh lên.
Giá trị của CPOL có thể được đảo lại bởi cổng NOT logic.
CPHA dựa trên việc định thời điểm (tức là phase) của dữ liệu bit tương ứng xung clock.
CPHA = 0 khi bit dữ liệu đầu ra đúng với xung SCK còn lại còn xung dẫn đầu rơi vào khoảng giữa của bit dữ liệu.
CPHA = 1 khi bit dữ liệu đầu ra đúng với xung SCK dẫn đầu còn xung còn lại rơi vào khoảng giữa của bit dữ liệu.
Từ đây, việc lựa chon các giá trị CPOL và CPHA sẽ tương ứng với 4 chế độ hoạt động trên SPI. 4 chế độ này được quy ước trên tất cả các dòng vi điều khiển có hỗ trợ SPI:
Mode
CPOL
CPHA
0
0
0
1
0
1
2
1
0
3
1
1
Chế độ SPI cũng thường được quy ước theo dạng tuple cho (CPOL, CPHA), ví dụ (0, 1) để chỉ CPOL=0 và CPHA=1.
Để truyền thông SPI thành công, cả master và slave phải có cùng chế độ (CPOL, CPHA). Việc lựa chọn 4 chế độ (CPOL, CPHA) không ảnh hưởng đến hiệu suất truyền SPI.
Kết nối từng slave độc lập
Một bus SPI với một master và 3 slave được kết nối độc lập
Mô hình phổ biến nhất của một bus SPI bao gồm một master kết nối với một hoặc nhiều slave, với các chân SCK, MOSI và MISO được nối đến tất cả các slave trên bus, mỗi slave sẽ kết nối đến một chân CS riêng trên master. Mỗi chân CS khi đó nên có một điện trở kéo lên để đảm bảo rằng chân CS đó luôn có mức logic xác định. Khi khởi tạo một giao tiếp SPI và một chân CS ứng với một slave được chọn. điện trở kéo lên này giúp ngăn chặn các chân CS của các slave phản hồi với master dù không được yêu cầu từ master này.
Kết nối daisy chain
Một bus SPI được kết nối theo mô hình daisy chain
Một số thiết bị triển khai SPI theo mô hình daisy chain, với chân MISO của slave đầu tiên được nối vào chân MOSI của slave thứ 2, và cứ thế tiếp tục như ở hình bên. Việc triển khai SPI trên mỗi slave khi đó cần phải đảm bảo rằng mỗi slave đó phải truyền đi được chính xác dữ liệu mà nó nhận được từ slave trước nó trong mỗi xung clock. Quá trình nhận và truyền dữ liệu đi trên các slave của bus SPI daisy chain sẽ kết thúc khi một chân/dây SS duy nhất trên bên được master ghi mức logic cao (chuyển từ logic thấp lên cao). Từ đó, mô hình SPI daisy chain chỉ sử dụng 1 chân SS trên đường truyền.
FRU là một bảng mạch in , bộ phận hoặc cụm lắp ráp có thể được tháo ra nhanh chóng và dễ dàng khỏi máy tính hoặc thiết bị điện tử khác và được người dùng hoặc kỹ thuật viên thay thế mà không cần phải gửi toàn bộ sản phẩm hoặc hệ thống đến cơ sở sửa chữa. FRU cho phép một kỹ thuật viên thiếu kiến thức chuyên sâu về sản phẩm có thể cô lập lỗi và thay thế các thành phần bị lỗi. Mức độ chi tiết của FRU trong một hệ thống ảnh hưởng đến tổng chi phí sở hữu và hỗ trợ, bao gồm chi phí dự trữ phụ tùng thay thế , nơi phụ tùng được triển khai để đáp ứng mục tiêu thời gian sửa chữa, cách thiết kế và triển khai các công cụ chẩn đoán, mức độ đào tạo cho nhân viên thực địa, liệu người dùng cuối có thể tự thay thế FRU của họ hay không, v.v.
FRU là các thành phần phần cứng của một thiết bị hoặc hệ thống có thể được thay thế tại chỗ mà không cần gửi toàn bộ thiết bị về trung tâm bảo hành hoặc nhà sản xuất. Những bộ phận này thường được thiết kế để dễ dàng tháo lắp nhằm giảm thời gian sửa chữa và bảo trì.
Ví dụ về FRU trong máy tính và thiết bị điện tử:
RAM (Bộ nhớ)
HDD/SSD (Ổ cứng)
PSU (Bộ nguồn)
Pin laptop
Card đồ họa
Quạt làm mát
Module mạng
FRU giúp giảm thời gian ngừng hoạt động của thiết bị, tiết kiệm chi phí sửa chữa và nâng cao hiệu suất vận hành trong môi trường doanh nghiệp cũng như cá nhân.
PlatformController Hub ( PCH ) là một họ chipset chip đơn của Intel , được giới thiệu lần đầu tiên vào năm 2009. Đây là sản phẩm kế thừa của Intel Hub Architecture , sử dụng hai chip – một cầu bắc và một cầu nam , và lần đầu tiên xuất hiện trong Intel Series 5 .
PCH kiểm soát một số đường dẫn dữ liệu và hỗ trợ các chức năng được sử dụng kết hợp với CPU Intel . Chúng bao gồm xung nhịp ( xung nhịp hệ thống ), Giao diện hiển thị linh hoạt (FDI) và Giao diện phương tiện trực tiếp (DMI), mặc dù FDI chỉ được sử dụng khi chipset được yêu cầu hỗ trợ bộ xử lý có đồ họa tích hợp . Do đó, các chức năng I/O được chỉ định lại giữa hub trung tâm mới này và CPU so với kiến trúc trước đó: một số chức năng cầu bắc, bộ điều khiển bộ nhớ và làn PCIe , đã được tích hợp vào CPU trong khi PCH tiếp quản các chức năng còn lại ngoài các vai trò truyền thống của cầu nam. AMD có tương đương với PCH, được gọi đơn giản là chipset kể từ khi phát hành kiến trúc Zen vào năm 2017. AMD không còn sử dụng tương đương của mình cho PCH, hub bộ điều khiển Fusion (FCH).
Tổng quan
Bộ điều khiển nền tảng Intel Cannon Lake Hub
Kiến trúc PCH thay thế Kiến trúc Hub trước đây của Intel , với thiết kế giải quyết tình trạng tắc nghẽn hiệu suất có vấn đề cuối cùng giữa bộ xử lý và bo mạch chủ . Theo Kiến trúc Hub, bo mạch chủ sẽ có một chipset hai mảnh bao gồm một chip cầu bắc và một chip cầu nam. Theo thời gian, tốc độ của CPU tiếp tục tăng nhưng băng thông của bus mặt trước (FSB) (kết nối giữa CPU và bo mạch chủ) thì không, dẫn đến tình trạng tắc nghẽn hiệu suất.
Để giải quyết tình trạng tắc nghẽn, một số chức năng thuộc về chipset cầu bắc và cầu nam truyền thống đã được sắp xếp lại. Cầu bắc và các chức năng của nó hiện đã bị loại bỏ hoàn toàn: Bộ điều khiển bộ nhớ, các làn PCI Express cho các card mở rộng và các chức năng cầu bắc khác hiện được tích hợp vào đế CPU như một tác nhân hệ thống (Intel) hoặc được đóng gói trong bộ xử lý trên một đế I/O (AMD Zen 2).
PCH sau đó kết hợp một số chức năng còn lại của cầu bắc (ví dụ như xung nhịp) ngoài tất cả các chức năng của cầu nam, thay thế nó. Đồng hồ hệ thống trước đây là kết nối với một chip chuyên dụng nhưng hiện được kết hợp vào PCH. Có hai kết nối khác nhau giữa PCH và CPU: Giao diện hiển thị linh hoạt (FDI) và Giao diện phương tiện trực tiếp (Flexible Display Interface DMI). FDI chỉ được sử dụng khi chipset yêu cầu hỗ trợ bộ xử lý có đồ họa tích hợp. Intel Management Engine cũng đã được chuyển đến PCH bắt đầu từ bộ xử lý Nehalem và chipset 5-Series . Thay vào đó, chipset của AMD sử dụng một số làn PCIe để kết nối với CPU đồng thời cung cấp các làn PCIe riêng của chúng, cũng được cung cấp bởi chính bộ xử lý. Chipset cũng chứa bộ nhớ BIOS không mất dữ liệu .
Với các chức năng của cầu bắc được tích hợp vào CPU, phần lớn băng thông cần thiết cho chipset hiện đã được giải quyết.
Phong cách này bắt đầu ở Nehalem và sẽ tiếp tục trong tương lai gần, thông qua Cannon Lake .
Loại bỏ dần
Bắt đầu với Haswell công suất cực thấp và tiếp tục với bộ xử lý Skylake di động , Intel đã kết hợp bộ điều khiển IO cầu nam vào gói CPU, loại bỏ PCH cho thiết kế hệ thống trong gói (SOP) với hai khuôn; khuôn lớn hơn là khuôn CPU, khuôn nhỏ hơn là khuôn PCH. Thay vì DMI , các SOP này trực tiếp phơi bày các làn PCIe, cũng như các đường SATA, USB và HDA từ bộ điều khiển tích hợp và các đường SPI/ I²C /UART/GPIO cho cảm biến. Giống như CPU tương thích với PCH, chúng tiếp tục phơi bày các đường DisplayPort, RAM và SMBus . Tuy nhiên, bộ điều chỉnh điện áp tích hợp đầy đủ sẽ không có cho đến Cannon Lake.
FCH của AMD đã ngừng sản xuất kể từ khi phát hành dòng CPU Carrizo vì nó đã được tích hợp vào cùng một khuôn với phần còn lại của CPU. Tuy nhiên, kể từ khi phát hành kiến trúc Zen, vẫn còn một thành phần gọi là chipset chỉ xử lý I/O tốc độ tương đối thấp như cổng USB và SATA và kết nối với CPU bằng kết nối PCIe. Trong các hệ thống này, tất cả các kết nối PCIe đều được định tuyến trực tiếp đến CPU. Giao diện UMI trước đây được AMD sử dụng để giao tiếp với FCH được thay thế bằng kết nối PCIe. Về mặt kỹ thuật, bộ xử lý có thể hoạt động mà không cần chipset; nó chỉ tiếp tục có mặt để giao tiếp với I/O tốc độ thấp. CPU máy chủ và máy tính xách tay AMD thay vào đó áp dụng thiết kế hệ thống trên chip (SoC) độc lập không yêu cầu chipset.
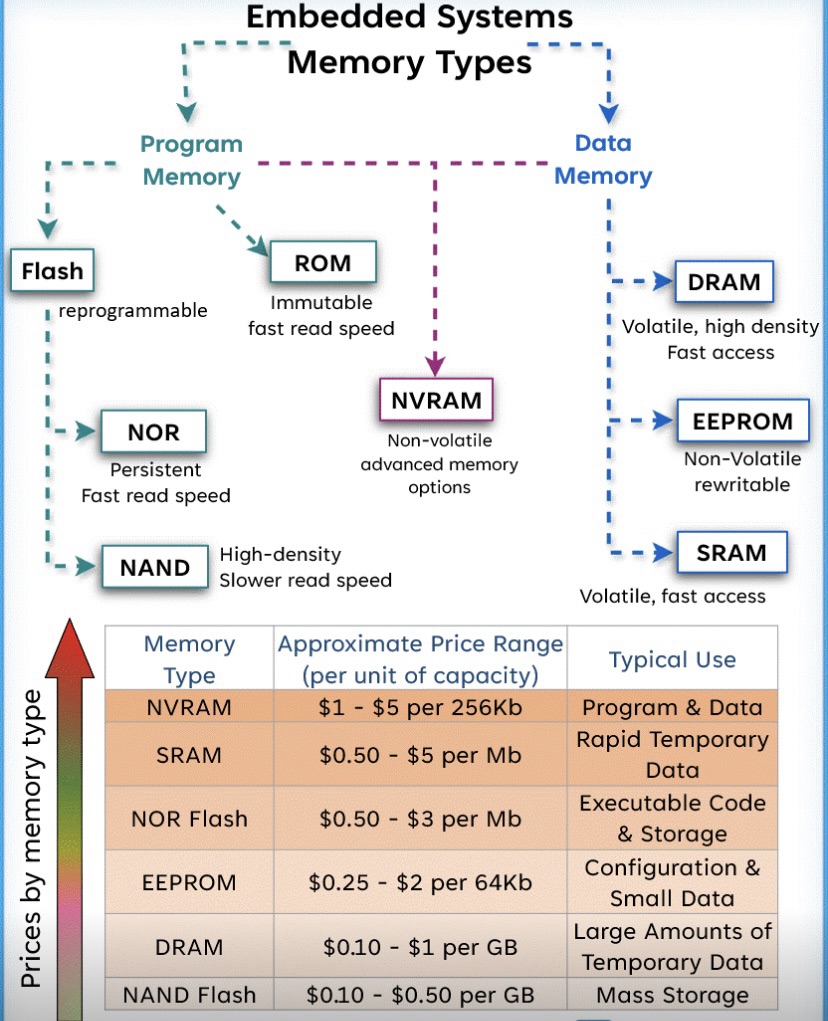
Hệ thống nhúng có mặt ở khắp mọi nơi, tích hợp liền mạch vào cuộc sống hàng ngày của chúng ta. Nhưng điều gì đứng sau sự tin cậy và hiệu quả của chúng? Đó chính là việc sử dụng chiến lược các loại bộ nhớ khác nhau:
NAND Flash: Một giải pháp lưu trữ không khả biến (không mất dữ liệu khi mất điện) nổi tiếng với dung lượng cao và độ bền lớn.
Ví dụ: Được sử dụng trong ổ cứng SSD để truy xuất và lưu trữ dữ liệu nhanh chóng, trở thành thành phần chủ chốt trong các thiết bị điện tử tiêu dùng như điện thoại thông minh và máy tính bảng.
DRAM: Bộ nhớ khả biến cung cấp khả năng truy cập dữ liệu tốc độ cao.
Ví dụ: Đóng vai trò trung tâm trong sức mạnh tính toán của PC và máy chủ, hỗ trợ xử lý nhanh và đa nhiệm.
EEPROM: Bộ nhớ không khả biến cho phép ghi và xóa dữ liệu bằng điện.
Ví dụ: Thành phần không thể thiếu trong các bộ điều khiển ô tô, cho phép xe lưu trữ các dữ liệu vận hành quan trọng và cài đặt của người dùng.
NOR Flash: Được biết đến với khả năng đọc nhanh và độ tin cậy cao.
Ví dụ: Tìm thấy trong các hệ thống nhúng yêu cầu thực thi mã trực tiếp từ bộ nhớ, chẳng hạn như trong máy ảnh kỹ thuật số và thiết bị y tế.
SRAM: Cung cấp khả năng truy cập dữ liệu cực nhanh, dùng để lưu trữ dữ liệu tạm thời.
Ví dụ: Thường được dùng trong vi điều khiển và CPU dưới dạng bộ nhớ đệm (cache), giúp tăng tốc độ truy cập các dữ liệu thường dùng.
NVRAM: Kết hợp độ bền của bộ nhớ không khả biến với khả năng truy cập nhanh của bộ nhớ khả biến.
Ví dụ: Được sử dụng trong các thiết bị mạng để lưu trữ thông tin cấu hình, đảm bảo các cài đặt được bảo toàn qua các lần tắt/mở nguồn.
ROM: Bộ nhớ chỉ đọc được lập trình sẵn với phần mềm vĩnh viễn.
Ví dụ: Được sử dụng trong các thiết bị gia dụng như lò vi sóng và máy giặt để lưu trữ firmware, điều khiển các chức năng cơ bản của thiết bị.
Mặc dù việc lựa chọn bộ nhớ ảnh hưởng đến hiệu suất thiết bị, nhưng hiểu được cách nó tác động đến chi phí cũng quan trọng không kém. Nếu bạn là một nhà phát triển đang tìm cách tối ưu hóa thiết kế hệ thống nhúng của mình cả về mặt kỹ thuật lẫn tài chính, việc so sánh các loại bộ nhớ là bước khởi đầu. Tuy nhiên, việc nắm bắt được giá cả chính xác và hiện hành có thể là một thách thức. Nếu bạn có thông tin chuyên sâu về giá bộ nhớ hoặc chiến lược thiết kế hệ thống nhúng tiết kiệm chi phí, những đóng góp của bạn sẽ vô cùng quý giá.
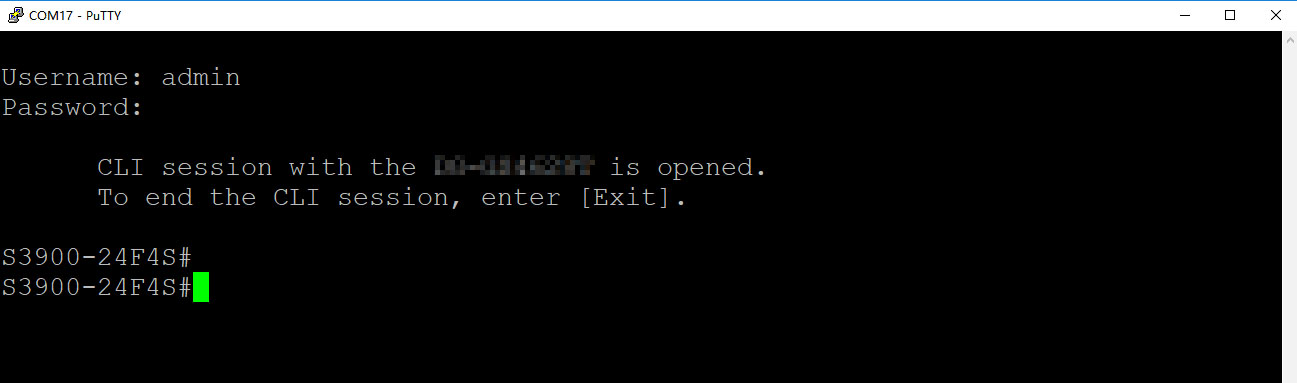
Để truy cập vào bộ chuyển mạch, thường ta sẽ truy cập từ xa bằng Telnet hoặc đăng nhập HTTP qua trình duyệt web. Tuy nhiên, ta có thể sử dụng cổng Console trên Switch để quản trị Switch mà không cần mạng. Trong bài viết này, ta sẽ tìm hiểu chi tiết xem cổng Console là gì? Chức năng của nó như thế nào và cách sử dụng nó ra sao!
Cổng Console là gì?
Cổng Console trên Switch là một cổng vật lý được tích hợp trên thiết bị, thường là cổng RJ-45 hoặc Mini-USB, được sử dụng để kết nối với máy tính hoặc thiết bị ngoại vi thông qua cáp console. Loại cổng này còn được gọi với cái tên khác như “cổng điều khiển”.
Chức năng của cổng Console là để các quản trị viên đăng nhập vào bộ chuyển mạch mà không cần kết nối mạng. Loại cổng này thường được sử dụng với mục đích như:
Cho phép quản trị viên kết nối với Switch từ xa thông qua giao diện dòng lệnh. Điều này giúp quản trị viên có thể thực hiện các tác vụ quản lý và cấu hình mà không cần phải trực tiếp tiếp cận thiết bị.
Cổng Console là một phương tiện quan trọng để thiết lập các thông số cơ bản và cấu hình mạng ban đầu.
Trong tình huống cần khôi phục thiết lập gốc hoặc giải quyết sự cố lớn, cổng Console là công cụ quan trọng để thực hiện quy trình khôi phục từ xa.
Cáp Console
Cáp Console là một loại cáp được sử dụng để kết nối thiết bị mạng, như Switch, Router, hoặc thiết bị mạng khác, với máy tính hoặc máy tính xách tay. Cáp này được thiết kế để tạo liên kết giữa cổng Console trên thiết bị mạng và cổng serial hoặc USB trên máy tính.
Cáp Console thường có một đầu kết nối phù hợp với cổng Console trên thiết bị mạng (thường là RJ-45 hoặc Mini-USB) và một đầu kết nối với cổng serial hoặc USB trên máy tính.
Phần mềm Terminal
Khi đã thiết lập kết nối thông qua cổng Console, bạn cần sử dụng phần mềm terminal để truy cập và tương tác với giao diện dòng lệnh của thiết bị mạng. Có 2 phần mềm Terminal phổ biến nhất là: PuTTY và SecureCRT
Phần mềm PuTTY:
Miễn phí và mã nguồn mở.
Hỗ trợ nhiều giao thức truy cập như SSH, Telnet, và Serial.
Giao diện đơn giản và dễ sử dụng.
Chạy trên nền Windows, nhưng cũng có thể sử dụng trên Linux.
Phần mềm SecureCRT:
Có phiên bản thương mại và cung cấp nhiều tính năng mạnh mẽ.
Hỗ trợ nhiều giao thức bảo mật như SSH, Telnet, và Serial.
Giao diện đồ họa chất lượng cao với nhiều tùy chọn tùy chỉnh.
Tích hợp tính năng kịch bản và tự động hóa.
Cách đăng nhập vào Switch bằng cổng Console
Để sử dụng cổng Console, ta sẽ thực hiện theo các bước sau:
Kết nối cổng Console trên Switch với máy tính sử dụng cáp Console phù hợp.
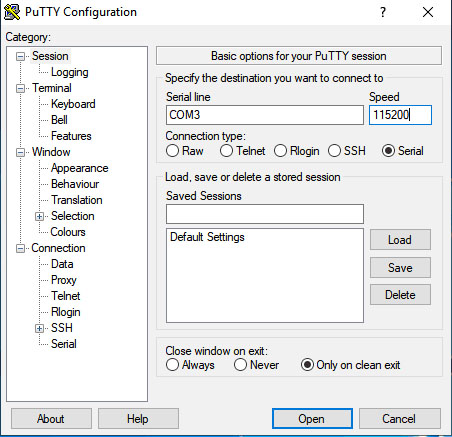
Mở phần mềm terminal trên máy tính. Trong phần mềm terminal, chọn loại kết nối là “Serial” hoặc “SSH” tùy thuộc vào cách bạn kết nối với Switch.
Nhập địa chỉ IP của Switch nếu sử dụng kết nối SSH hoặc chọn cổng Serial tương ứng. Cấu hình các thông số kết nối như tốc độ baud, bits dữ liệu, parity, stop bits theo yêu cầu của Switch.
Nhấn nút “Open” hoặc “Connect” để mở kết nối. Màn hình terminal sẽ hiển thị cửa sổ đăng nhập. Nhập tên đăng nhập và mật khẩu để truy cập vào giao diện dòng lệnh của Switch.
Thiết lập thông số kết nối
khi thiết lập kết nối thông qua cổng Console, quan trọng nhất là cấu hình đúng các thông số kết nối. Dưới đây là thông tin về các chỉ số và cách thiết lập.
Tốc độ Baud (Baud Rate): Đây là tốc độ truyền dữ liệu giữa thiết bị và máy tính. Thông thường, tốc độ baud phải được đặt cùng nhau ở cả hai đầu của kết nối. Một giá trị phổ biến là 9600 baud, nhưng tùy thuộc vào thiết bị, bạn có thể cần điều chỉnh giá trị này.
Bits Dữ liệu (Data Bits): Số bits dữ liệu xác định số bit thông tin được truyền trong mỗi ký tự. Thông thường, giá trị này là 8 bits, nhưng cũng có thể là 7 bits hoặc 9 bits tùy thuộc vào cấu hình thiết bị.
Parity (Chẵn Lẻ): Parity là một bit kiểm tra được thêm vào ký tự để kiểm tra lỗi truyền dẫn. Có ba loại parity chính: chẵn (even), lẻ (odd), và không có parity. Bạn cần đảm bảo rằng cả thiết bị và máy tính cùng sử dụng loại parity tương tự.
Stop Bits: Stop bits xác định kết thúc của mỗi ký tự và được thêm vào sau dữ liệu và parity. Thông thường, giá trị này là 1 stop bit, nhưng cũng có thể là 1.5 hoặc 2 stop bits.